本文是一篇计算机论文,笔者认为随着计算机的技术的迅猛发展,数据库等相关数据存储技术也日益完善,能够提供充足的内存空间用于存放海量的非结构化文本于互联网中,同时面对竞争日益激烈的市场环境,政府对于企业的相关扶持政策也在不断进行调整,每隔一定时间,就会发布适合当前市场的相关扶持政策引导和帮助企业发展。
第一章绪论
1.1研究背景与意义
企业经济是国家经济体系中极为重要的组成部分,企业的稳定发展是政府一直以来的关注重点。为了更好的引导企业发展,同时规范企业的生产营销行为,政府发布了相关政策法规,其中企业扶持政策作为国家、省、市等各级政府部门支持企业发展所公开发布的税收减免、项目补贴、信贷支持、资质认定等一系列措施,在政府对于企业扶持引导的工作上起到了较大的作用。政府发布最早的企业扶持政策时间是在1988年6月,当时的个体经济已开始逐渐向私营企业经济转化,偏离国家对于个体工商户经营行为的规定,但为了更好的发展经济,同时不打击个体商户的工作热情,经过多次的讨论分析,最终决定为私营企业和私营经济通过了《中华人民共和国私营企业暂行条例》的立法,并由国务院颁布了该政策。该政策的发布与实行确立了企业这种私营经济的合法地位,扫清了私营经济发展的障碍,为私营经济的发展营造了良好的法制环境与制度环境,极大的鼓舞了个体工商户和私营企业家的工作热情,因此在政策发布实行后的几个月,全国的私营企业从无到有,迅速发展到9.06万家,同时从业人员达到约163.1万人。政府历年来为了更好地支持私营企业稳定快速发展,根据社会发展态势不断调整关于企业扶持政策,从1988年到2012年,全国各地的私营企业数量已突破到1085.72万户,且企业的注册资金总量也上升至31.1万亿元,随着企业数量的急剧增加,在带动中国经济繁荣发展的同时,也产生了大量的职业岗位,因此全国的从业人员增加到11296.1万人。近年来,随着企业的蓬勃发展,从政策角度对企业发展进行研究已成为专家学者的关注焦点[1-3]。如学者分析在新冠疫情爆发时[4],针对企业的困境,政府发布的企业扶持政策中对哪些措施进行调整可以有效帮助企业渡过难关。同时学者对效果较好的扶持措施进行总结,并为后续政府面对这些可能发生的类似突发危机时应该采取何种行动建言献策。随着计算机技术的快速发展,大量企业扶持政策文本数据以非结构化的形式存储于政府网站中[5-8],且企业扶持政策文本中含有大量术语,传统自然语言处理领域任务在企业扶持政策文本上的表现不佳[9-11]。
.................
1.2国内外研究现状
命名实体识别技术来源于1991年第七届人工智能应用会议,由Rau等[21]人提出的可以从文本中识别公司名称的实体识别系统。之后在1996年的第六届消息理解会议上由Grishman等[22]人正式提出“命名实体”概念。自此以后,命名实体识别算法引发了众多学者的研究热情,算法技术不断被学者们创新完善,产生了大量应用于各个领域的理论和模型。命名实体识别的相关算法大致可以分为以下三种:
(1)基于规则和词典
作为早期命名实体识别研究工作的主要方法,是基于大量相关领域文本的总结归纳,由相关领域专家根据语法和自身经验制定得到。Fukuda等[23]人利用从生物医学文本提取出的关键词,进行总结归纳制定出规则模块,最后将得到的规则模块应用于文本。针对通用命名实体识别模型从科学报告文本中提取饮食建议的实体信息效果不佳的问题,Eftimov等[24]人提出了一种基于规则的drN ER方法,经实验验证,在面向科学健康报告文本的命名实体识别任务中,该方法能够有效提取实体信息。Popovski等[25]人基于计算语言学和描述食物实体的语义信息,提出了一种基于规则的FoodI E方法,实验结果表明,该方法能够从非结构化文本中提取出食品实体信息。基于规则和词典的方法可以根据自定义规则从文本语料中获取到符合的实体,但规则的制定依赖于领域专家对领域知识的掌握以及对领域特征的总结,同时依据单一领域定义的规则和模板在其它领域任务的泛化能力较差。
(2)基于机器学习的方法。
机器学习的概念在1959年由Arthur Lee Samuel提出。基于统计和机器学习的方法主要是通过对大量语料进行训练,利用统计特征和机器学习算法来识别和提取实体信息。随着研究的不断深入和完善,基于统计和机器学习的方法逐渐取代基于规则的方法,以支持向量机(SVM)、隐马尔科夫(HMM)、条件随机场(CRF)为代表的机器学习算法在各个领域得到了广泛的应用。黄浩炜[26]通过抽取上下文特征、词性特征、核心特征等特征集合,进行模型训练,得到SVM分类器,最后利用错误驱动学习方法对模型预测结果进行校正。
.......................
第二章相关概念与理论基础
2.1命名实体识别的相关概念
命名实体识别任务能够识别文本语料中人为定义的实体类别,从文本语料中挖掘重要的实体信息,实现非结构化文本数据向结构化数据的转化。命名实体识别任务主要分为基于规则和词典的方法、基于机器学习的方法、基于深度的方法,其中基于深度学习的命名实体识别方法在各个领域应用较为广泛,本文选择基于深度学习的算法在企业扶持政策文本上执行命名实体识别任务。基于深度学习的命名实体识别方法需要构建神经网络模型,并利用输入文本语料作为训练样本对模型进行训练,文本语料作为模型的输入时,必须将输入语料从非结构化数据转为结构化数据后,才能作为训练样本数据投入到模型训练,而这种将输入文本由非结构化数据转为结构化数据的过程称为文本向量化表示,即将由字符构成的输入语句转为向量序列,然后使用训练得到的模型在企业扶持政策文本的测试数据集上进行实体识别。文本向量化表示是数据预处理中一个重要步骤,能够影响到模型训练过程中对于输入语料的语义信息获取。文本向量化表示方法大致可以分为离散式向量表示方法和分布式向量表示方法两种,其中离散式向量表示方法认为输入文本语料是由离散符号构成,每一个离散符号对应文本空间的一个节点,因此将输入文本语句中的字符通过离散式向量表示方法逐一转为向量后,这些向量能够构成一个高维的向量空间。通过离散式向量表示方法得到的高维向量空间可以将许多线性不可分任务转化为线性可分任务,但这种方法会忽视词汇间的联系;分布式向量表示方法认为输入文本语句是由词汇组成的,词汇间存在着密切的联系,通过分布式向量表示方法可以将输入文本语句中的每个词汇转为稠密向量,用以表征词汇间的上下文联系。
.............................
2.2命名实体识别的理论基础
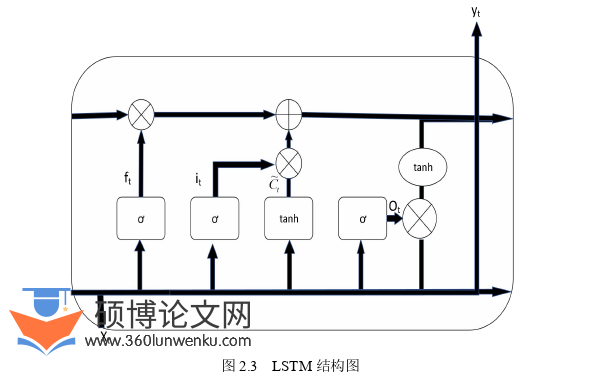
2.2.1双向长短时记忆网络BiLSTMLSTM
模型通过引入门结构和记忆细胞,能够有效解决RNN模型在更新参数时易出现的梯度爆炸和梯度消失问题,从而使得LSTM在处理长序列数据时的效果更佳。LSTM模型中通过三种门结构来保护和控制信息状态,其中输入门是用于更新细胞状态;遗忘门的作用是上一时刻信息的保留程度;输出门的作用是输出下一个时刻隐藏状态的值。LSTM的结构如图2.3所示:
计算机论文怎么写
......................
第三章 企业扶持政策文本数据集的构建 ....................... 19
3.1 企业扶持政策文本的相关概念 ............................... 19
3.1.1 企业扶持政策文本的内容分析 .............................. 19
3.1.2 企业扶持政策文本的结构分析 ............................. 20
第四章 基于 RoBERTa-wwm 的企业扶持政策文本的实体识别研究 .......................... 26
4.1 模型结构解析 ........................... 26
4.2 实验流程 ................................ 29
第五章 基于字词融合的企业扶持政策文本的实体识别研究 ............ 36
5.1 模型介绍 ................................... 36
5.1.1 模型结构概述 ................................. 36
5.1.2 向量表示层 .................................... 37
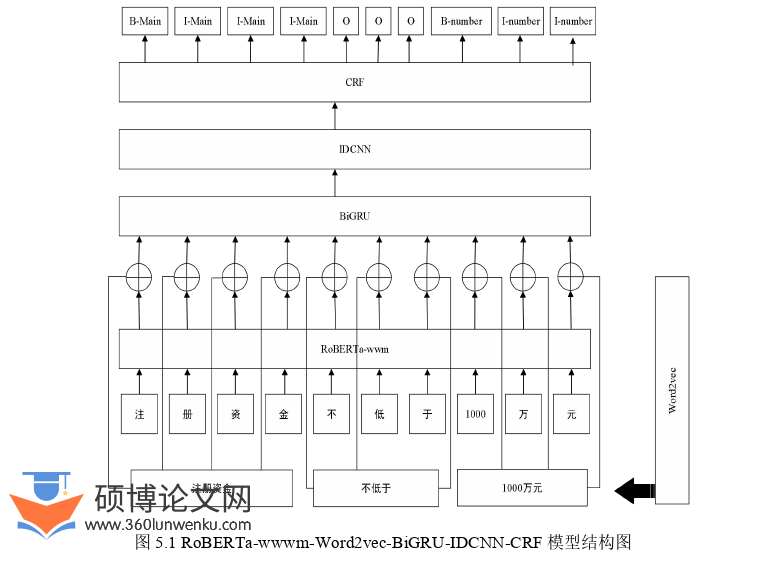
第五章基于字词融合的企业扶持政策文本的实体识别研究
5.1模型介绍
RoB ERTa-wwm是基于双向transformer编码器的预训练模型,将输入文本语句按字符级切分后得到的字符序列作为输入,然后通过transformer编码器对输入字符序列进行编码,最后生成相应的字向量输出。因此,将RoB ERTa-wwm作为命名实体识别模型的输入模块,能够提高模型的表达能力和泛化能力,从而得到更好的文本表示结果,但RoB ERTa-wwm预训练模型在进行下游任务时着重于字符级特征信息的获取,对于词汇级特征信息的抽取能力相对薄弱,而中文文本语料有别于以单词作为基本构成单元的英文文本,主要由大量词汇构成,若以单一RoB ERTa-wwm作为企业扶持政策文本实体识别模型的输入模块,则会使得实体识别模型无法从企业扶持政策文本数据集中获取充分的词汇级特征信息,最终影响模型在企业扶持政策文本测试数据集上的实体识别精度。相比之下,以Word2vec为首的词向量模型能够将输入文本语句按词汇划分后得到的词汇序列作为输入,然后从企业扶持政策文本数据集中抽取丰富的词汇级特征信息。综上所述,考虑到RoB ERTa-wwm能够从企业扶持政策文本数据集中获取字符级特征信息和Word2vec词向量模型能够获取丰富词汇级特征信息的特点,本章提出基于字词融合的企业扶持政策文本命名实体识别模型。
计算机论文参考
.........................
第六章总结与展望
6.1工作总结
随着计算机的技术的迅猛发展,数据库等相关数据存储技术也日益完善,能够提供充足的内存空间用于存放海量的非结构化文本于互联网中,同时面对竞争日益激烈的市场环境,政府对于企业的相关扶持政策也在不断进行调整,每隔一定时间,就会发布适合当前市场的相关扶持政策引导和帮助企业发展,因此随着时间的流逝,涉及不同行业领域的扶持政策文件杂乱无章的堆积在政府网站中,企业扶持政策文本作为非结构化形式的数据,计算机无法直接进行处理,而命名实体识别能够从未经标注的文本数据中挖掘出实体信息,将文本转为结构化数据。本文致力于研究将企业扶持政策文本中蕴藏的实体信息挖掘出来,提出了两种神经网络模型用于企业扶持政策文本的实体识别任务,并在自建的企业扶持政策文本数据集上进行验证。具体而言,本文的主要工作总结如下:
(1)由于企业扶持政策文本的实体标注语料较为稀少,本文对企业扶持政策文本的内容和结构进行了深入研究,并对其中的重要信息字段进行了归纳总结。随后,自定义了实体类别,并对经过数据预处理后的企业扶持政策文本数据集进行了实体标注,得到了大量的企业扶持政策文本实体标注语料,用于模型的训练、优化以及性能评估。这种方法不仅提高了实体标注语料的数量和质量,更重要的是可以提高模型的泛化能力,从而提升企业扶持政策文本实体标注的准确性和效率。
(2)针对传统命名实体识别模型在企业扶持政策文本中存在实体识别效果较差的问题,提出了一种基于RoB ERTa-wwm和BiL STM-CRF相结合的新型命名实体识别模型。该模型利用RoB ERTa-wwm编码器将输入的字符级扶持政策文本序列转换为动态字向量,再将其作为BiL STM的输入,利用BiL STM获取输入文本语料的上下文特征信息,最后通过条件随机场CRF获得最佳预测标注序列。实验结果表明,在自建数据集上,该模型的F1值达到了91.70%,表明该模型能够有效识别扶持政策文本语料中的实体信息。同时,与传统模型进行实验对比,结果显示该模型在性能上优于传统的命名实体识别模型。因此,本文提出的基于RoB ERTa-wwm和BiL STM-CRF相结合的命名实体识别模型具有较高的实用价值。
参考文献(略)